


最近、なんか知らんが怒りっぽい。多分、原因は十数年飲んでた炭酸リチウム無くしたからかなぁと勝手に思ってる。
まぁ昼間の眠気やらやたらと早い就寝やらしなくて済むようになったので助かってるんだが、どーも感情制御が上手く行かなくて、突然切れたり切れそうになったりするので困る。仕事場でもそんな感じになるし。
アンガーマネジメントも余り上手くいかん。致命的なことにならないように気をつけたいのだが。どうすんべな。
最近、なんか知らんが怒りっぽい。多分、原因は十数年飲んでた炭酸リチウム無くしたからかなぁと勝手に思ってる。
まぁ昼間の眠気やらやたらと早い就寝やらしなくて済むようになったので助かってるんだが、どーも感情制御が上手く行かなくて、突然切れたり切れそうになったりするので困る。仕事場でもそんな感じになるし。
アンガーマネジメントも余り上手くいかん。致命的なことにならないように気をつけたいのだが。どうすんべな。
1月23日(火)、近所のペットワイドで新たなデグーをお迎えした。名前は玄斗(げんと)君。
生後7ヶ月くらい。
セール価格になっていて、7ヶ月。場合によっては処分される可能性もある。そういう言い訳をしながらお迎えすることにした。ついついハヤテ君の影を追ってしまうのがきつかったのもある。
毛が黒っぽいので玄斗君と名付けたのだが、なんかそういう名前の中国武将とか天部衆とか居そうだ。
この子はすごく慣れていて、お迎えしたその日には撫でさせてくれたし、翌日には呼ぶと来るようになった。
ただ、最初はうちの床鳴り(うちは古い家なのだ)が怖くて大騒ぎだったけど、もう慣れてきてる模様。
かなり甘えん坊で図太い。もう横になって寝たり、私が動いてもあまり気にする様子も無い。
もう少し様子を見て、お散歩用のケージでも設置して遊ばせてみようかな。



眠気対策で色々変わったので更新。
| 薬剤名 | 量 | 服用 | 説明 |
| ラモトリギン100mg | 100mg×2 | 朝 | 適応は抗てんかん薬として、また双極性障害の気分エピソードの抑制である。 |
| アキネトン1mg | 0.5mg×1 | 朝 | 中枢神経に作用することにより、手のふるえ、筋肉のこわばりや動作が遅くなったりするのを改善します。 |
| アナフラニール10mg | 10mg×1 | 朝 | 憂うつな気分をやわらげ、意欲を高めるお薬です。 |
| バイカロン25mg | 25mg×0.5 | 朝 | 尿の量を増やし、血圧を下げるお薬です。 |
| ユリノーム | 25mg×0.5 | 朝 | 尿酸が尿中に排除されるのを促して、体内に尿酸が溜まるのを押さえる薬です。 |
| フェブキソスタット20mg | 20mg×1 | 朝 | 体内で尿酸が作られるのを押さえて、血中の尿酸の量を減らす薬です。 |
| テルミサルタン | 40mg×1 | 朝 | 高血圧症の治療に用いられます。 |
パソコン環境が大きく切り替わった話。
昨年末12月末、メインマシンをデュアルブートにしようと思ったのが運の尽きであった。
Windowsマシンの切り分けとUbuntuインストールまでは上手く行ったのだが、NVMEの認識が出来ず起動できない。
ネットを調べChatGPTに聞きながら色々と試すが、状況は悪くなるばかり。
結局12/31早朝、マザーボードが壊れてしまった。
それから、串刺し未遂事件が起こったのだが、パソコンが動かないと仕事が出来ない。
宮崎のパソコン工房にマザボなどを買いに行こうとするが、実家の家族に反対される。結局鎌倉から戻ってた弟に送り届けて貰う事になった。
CPUとマザボをIntel系に切り替えるが、状況変わらず。
最終的にKernelに関してまで調査して、ようやく原因が分かる。私がメインで使っていたSSDのGenが進みすぎててKernel対応してなかったのだ。
色々見てみるとKernelを自力でコンパイルすれば行けるようなことも書いてあるが、私がそれを実行しても後の保守が出来ない。
泣く泣くメインのSSDを外す。そうすると、今度はグラボの2枚差しも上手く行かない。これも結局1枚刺しに戻すことになった。
何だかんだで動くようになったのは6日。仕事が始まる直前。しかし、その間にWindows環境も死んでしまいノートでしか仕事が出来ない。Officeの授業などがあるからUbuntuだけでは仕事が完結しないのである。
9日、残ったグラボやSSD、以前使っていた電源などにマザボとCPUを買い足してWindows機が出来上がった。
OSや環境は、AcronisのUniversalRestoreツールで問題なく復元できた。しかし、ほんとにこれすごいな。助かってます。
それからubuntuは23.10から22.04になり、CUDAなどを入れ直している最中である。テスト期間が近く、余り余裕がないのだ。
フロントをWindows、バックをUbuntuにして独自アプリなんかも作りやすくなった。金は飛んだし時間も吹っ飛んだが、塞翁が馬になるとよいな。
まぁしかし、VPSと実機ではまるで違う。もちろんWindowsとUbuntuも。これまでより高度なことが出来るようになった分、面倒な事も増えた。
イい年(52)になってからの学習はキツイが、まぁ頑張ろう。
Windows機
| 部品名 | 製品名 | 購入日 |
| CPU | Intel Core i5-13400F | 2024/1/9 |
| CPUファン | レファレンス | 2024/1/9 |
| マザーボード | PRIME B760M-K D4-CSM パソコン工房限定モデル | 2024/1/9 |
| メモリ | TED432G3200C22DC01 [DDR4 PC4-25600 ] | 2024/1/9 |
| グラボ | GG-RTX3060-E12GB/OC/DF | 2023/8/24 |
| SSD | G-Storategy NV47004TBY3G1 | 2023/9/1 |
| HDD | ST4000DM004-2CV104 | 2017/11/11 |
| ガワ | zalman t3 plus | 2024/1/9 |
Ubuntu機
| 部品名 | 製品名 | 購入日 |
| CPU | Intel Core i5 13400F | 2023/12/31 |
| CPUファン | レファレンス | 2023/12/31 |
| マザーボード | MSI PRO B760-P WIFI DDR4 | 2023/12/31 |
| メモリ | v-color Hynix IC DDR4 4266MHz 64GB | 2022/11/30 |
| グラボ | MSI GeForce RTX 3080 VENTUS 3X PLUS 12G OC LHR | 2022/11/9 |
| SSD | intel ssdpeknw020t9(Intel SSD 665p 2T) | 2020/10/4 |
| HDD | ST4000DM004-2CV104 | 2017/11/11 |
| 電源 | 玄人志向 KRPW-GR1000W/90+ | 2023/8/24 |
| ガワ | Antec P10 FLUX | 2021/6/23 |
| ディスプレイ | Acer VG240YUbmiipfx | 2022/4/17 |
| 液タブ | XP-Pen Artist 24 | 2022/3/11 |
| VRHMD | Pimax 5KSuper | 2021/11/23 |
今回は先日亡くなったハヤテ君について
16日18時半頃、7年半飼ってきたデグーのハヤテ君が急死しました。
2016年タロウ君がまだ生きていたときに彼はやって来ました。パイド柄の可愛い彼はとても臆病でずっと慣れてくれませんでした。それでもここ1年ほどは加速度的に距離が近づきとても楽しい日々を送ることが出来ていました。
年が明けてからは自主的に手に載るようになって私を非常に喜ばせてくれました。
しかし、昨年年末頃から、たまに苦しそうな様子を見せること、もともとウンチが細かったのが最近更に小さくなってしまっていたこと、水を余り飲まないことから、昨年12月くらいからケージにカバーを付けたりシートヒーターを増やしたり、ケージの足回りを再配置したりしていました。
年が明け、徐々に調子を取り戻しうんちがこれまでで一番ちゃんとしてる様子を見て安心していた矢先のことでした。
夕方、ケージの掃除を行っていました。
私はステージを水拭きし、ハヤテ君は部屋ん歩し、ストーブの前で暖を取っていました。ハヤテ君は突然具合が悪くなったのか姿勢を崩します。ご存じの通り、小動物が苦しい様子を見せるのは余程のことです。彼はケージに戻りしばらくした後、大きく鳴き走り回ります。
パニックを起こしたように走り回るハヤテ君を、私は捕まえようとしますが、彼は私の手を見て更に逃げ惑うため捕まえられません。
そして、困惑し名前を呼ぶしか出来ない私の目の前で彼は倒れ、死んでしまったのです。
私は困惑し、しばらくは呆然とするしか有りませんでした。
そのうち涙がこぼれてきました。泣くことしかできませんでした。
祖父母や親友が亡くなったときにも涙が出なかったのに、ペットの死に涙が出る私は何かおかしいのではないかと思ったりしながら泣きました。
次の日仕事が有ること、晩ご飯や風呂のこと、彼の葬儀のこと、などなど様々な事が一気にあふれました。
2時間ほど感情的な時間が過ぎ、私は動き始めます。風呂に入り食事を摂り明日の仕事の準備をします。
しばしば彼の亡骸が動いたように見え、振り返りますが、そうなりません。
何かする度に私は彼のことを考慮に入れて過ごしていたのだと気付かされました。
ドアを開けるとき、夜中にトイレに行くとき、ご飯を食べるとき、買物に行くときetc。
その夜、ハヤテ君をケージのベッドに横たえ、翌日の夕方埋葬しました。
昨日、3Dプリンターで墓標を作りました。光造形の3Dプリンターですが、ABS樹脂風なので、屋外でもしばらくは保つでしょう。
彼の死もつらいですが、悲しいことがあります。
私はもう新しいペットを飼いたいと思っているのです。酷い話です。
彼の魂に誠実では無いと思いながらもです。人が知れば後ろ指を指すかも知れません。しかし、話しかける相手が居なくなり、彼のことを思い出してキツくなるのです。逃避なのかも知れません。
どれくらいの時間をおくべきなのか、私には分かりません。
ただ、もう少し心が平穏になるまでは間を置きたいです。そうでないと彼が可哀想だと思うのです。
新しいペットにも悪いと思います。もっとニュートラルな気持ちで迎えて上げたいです。
でも、一人はきついです。
ハヤテ君有難う。一人はキツいけど、君には前を向いて輪廻の旅をしてもらいたいです。
君の魂が、次の人生ではもっともっと幸せでありますように。


2024年は元旦から、能登沖の大震災や航空機事故が発生し大変です。
年末に、私の方も一つ間違うと死にそうなことになっていました。
実家には氏神様の小さな祠があります。しめ縄と竹で作られた鳥居のようなものがあり、その竹は毎年取りに行きます。ただ、最近は竹も少なくなり取るのに苦労しています。そろそろ何か代替品を探さないと駄目だろうと話していたところでした。
大晦日、弟と竹取りに向かいましたが、なかなか良いものが見つかりません。見つけたと思ってもほしい種類と違っていたり、取りにくい場所に有ったり。
散々うろついてやっと見つけた竹はとても背が高く、そのままでは刈り取ることができそうにありませんでした。
私は竹の根本に行き体重を掛けて曲げにかかります。弟が先を受け取って切り取るという役割分担です。
ぐいっと曲げますが、なかなか思ったところまで曲がりません。思い切り体重を掛けたところで竹が大きな音とともに折れてしまいました。
周囲は斜面で、踏ん張ることもできません。地面には尖った竹の切り株。なんとか周囲を掴んで串刺しこそ逃れましたが、喉と水月(胃)、左脛には大きなキズが残りました。特に水月には大きな傷と内出血があり、1週間以上経った今も完治していません。
もし、もう少し体重がかかっていたのなら串刺しだったのでしょう。
多分、私が生きてきた中で一番死に近づいた事故だったと思います。
来年からは何らかの代替品を使います。命有っての物種ですしね。
8/24にローカルLLMの大きなサイズを動かすためにグラボ(RTX3060-12G)を追加した。それに併せて電源を750Wから1000Wに変更。
8/31にDドライブのSSDが呼称したために9/1にSSDの4Tを購入。
Cドライブが2T→4T。Dドライブが1T→2Tへ。旧CドライブがDドライブへ、Cドライブは新規購入部品に変更。
SSDはBIOSがおかしかったのか、リストアで何かおかしな事をしたのか、リストア後にCドライブが起動せず苦労した。物は9/2朝に届いたのだが、復旧完了したのは9/3夕方であった。
現在の構成は以下の通り。
| 部品名 | 製品名 | 購入日 |
| CPU | AMD Ryzen 5 5600X | 2021/6/23 |
| CPUファン | 虎徹Ⅱ | 2021/6/23 |
| マザーボード | ASUS TUF GAMING B550-PLUS | 2021/6/23 |
| メモリ | v-color Hynix IC DDR4 4266MHz 64GB | 2022/11/30 |
| グラボ | MSI GeForce RTX 3080 VENTUS 3X PLUS 12G OC LHR | 2022/11/9 |
| グラボ | GG-RTX3060-E12GB/OC/DF | 2023/8/24 |
| SSD | G-Storategy NV47004TBY3G1 | 2023/9/1 |
| SSD | intel ssdpeknw020t9(Intel SSD 665p 2T) | 2020/10/4 |
| HDD | ST4000DM004-2CV104 | 2017/11/11 |
| HDD | ST4000DM004-2CV104 | 2017/11/11 |
| 電源 | 玄人志向 KRPW-GR1000W/90+ | 2023/8/24 |
| ガワ | Antec P10 FLUX | 2021/6/23 |
| DVD-RAM | LITEON? | 不明 |
| ディスプレイ | Acer VG240YUbmiipfx | 2022/4/17 |
| 液タブ | XP-Pen Artist 24 | 2022/3/11 |
| VRHMD | Pimax 5KSuper | 2021/11/23 |
一昨日、昨日と頑張ってた「Japanese StableLM Alpha」なのだけど、とりあえず他のから動かしてみて、実績を作る事にした。そのうち、分からなかったところも治せるようになるだろう。
そんなわけで今朝は「rinna/bilingual-gpt-neox-4b-instruction-ppo」をCtranslate2で量子化して動かす事にチャレンジ。
主にこちらを参照に。他にも色々見てたのだけど訳が分からなくなってしまった。
# 環境作成
pyenv local 3.10.10
python -m venv .venv
.venv/Scripts/activate
python -V
pip install --upgrade pip
python -m pip install --upgrade pip
#torchのインストール
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# ctranslate2インストール
pip install ctranslate2
pip install sentencepiece transformers
pip install protobuf
# 変換
ct2-transformers-converter --model rinna/japanese-gpt-neox-3.6b-instruction-ppo --quantization bfloat16 --force --output_dir rinna-ppo-bf16
変換は、bfloat16にしてみた。この状態で動かしても6G程度。変換で使用したメインメモリは20G程度だったかな?(うろ覚え)応答も十分早く、遅延は気にならなかった。
最終的に動かしたコードは以下の通り。
import ctranslate2
import transformers
import torch
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0" #GPUを使用する場合はコメントアウトを外す
model='rinna-ppo-int8' #directory of the model
ppo = "rinna/japanese-gpt-neox-3.6b-instruction-ppo"
generator = ctranslate2.Generator(model, device="auto")
tokenizer = transformers.AutoTokenizer.from_pretrained(ppo, use_fast=False)
# プロンプトを作成する
def prompt(msg):
p = [
{"speaker": "ユーザー", "text": msg},
]
p = [f"{uttr['speaker']}: {uttr['text']}" for uttr in p]
p = "<NL>".join(p)
p = p + "<NL>" + "システム: "
# print(p)
return p
# 返信を作成する
def reply(msg):
p = prompt(msg)
tokens = tokenizer.convert_ids_to_tokens(
tokenizer.encode(
p,
add_special_tokens=False,
)
)
results = generator.generate_batch(
[tokens],
max_length=256,
sampling_topk=10,
sampling_temperature=0.9,
include_prompt_in_result=False,
)
text = tokenizer.decode(results[0].sequences_ids[0])
print("システム(ppo-ct2): " + text + "\n")
return text
if __name__ == "__main__":
# import readline
while True:
msg = input("ユーザー: ")
reply(msg)
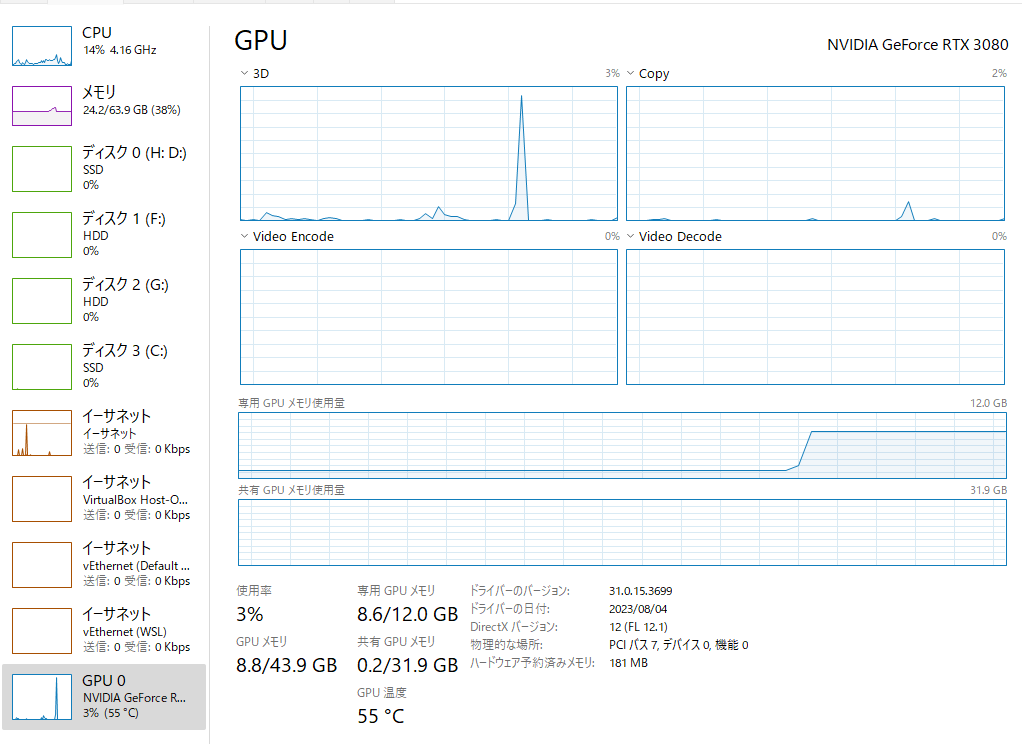
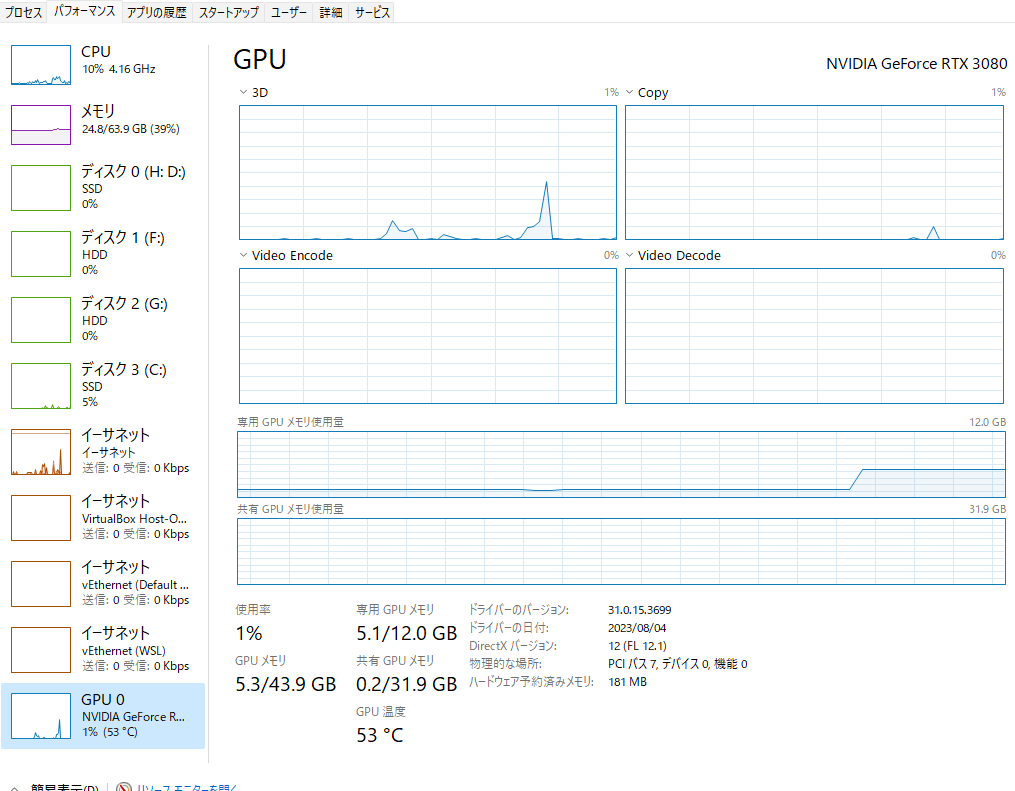
次にint8でも実行してみた。VRAMは4Gほどか?応答速度は、これも気にならなかった。応答精度も高い。
先日公開された「apanese StableLM Alpha 7B」をローカルで動かせないかチャレンジ中。
自分の環境はWindows11+VRAM12Gbなので8bit化しないと動かない。公開されている記事の多くはGoogleColabでそのままでは自分の環境では使えない。Windows11での記事も一箇所見つけたのだけど、公開されているサンプルをそのまま動かしていたので、VRAMも潤沢なのだろう。私が詰まっているポイントでは参考できない。
そもそも私はAIの事を勉強したことはない。昨年のAIブームを受けて騒いでいるミーハーだ。でもまぁこれを機会に自分なりの物を作ってみたいと思っている。langflowとやらを使えば何とかなるんじゃ無いかと思っているんだが。
Windows11ローカルが駄目ならWSL2。そっちの方が楽という呟きもちょいちょい見ているので、駄目ならそっちに行こうと思って居る。
もしくはRinna4Bも作例が多いように思って居るのでそっちから手を付け直しても良いのかも。いや、むしろそっちの方が良くないかなぁ。
ちょっと調べて、考えてみる。
これまで使ってたコルセアのゲーミングチェアが壊れた。しばらく前に機械油の匂いがするんだがなんだろう。と思ってたら椅子の高さが下がるようになってしまった。
昨日、とうとう駄目になった。一回高さを上げても10分も経つと戻ってしまう。しゃーないので買うことにした。
コルセアのを買うときに市内のお店巡ったんだけど、かなり苦労したので宮崎市のアプライドに言うことにした。
行って置いてあった椅子に座ってみておおよそ決めたところで店員さんを呼ぶ。聞いてみるとほとんど在庫が無い。候補の一つに在庫があったので買うことに決めた。カラーバリエーションが赤しか無くてちょっともにょったが、まぁいいか。
買ったのはMSIのゲーミングチェア。おおよそ3万円くらいの奴。