一昨日、昨日と頑張ってた「Japanese StableLM Alpha」なのだけど、とりあえず他のから動かしてみて、実績を作る事にした。そのうち、分からなかったところも治せるようになるだろう。
そんなわけで今朝は「rinna/bilingual-gpt-neox-4b-instruction-ppo」をCtranslate2で量子化して動かす事にチャレンジ。
主にこちらを参照に。他にも色々見てたのだけど訳が分からなくなってしまった。
前提条件
- windows11
- Python3.10.10
- 仮想環境はpyenv + venvで作成
# 環境作成
pyenv local 3.10.10
python -m venv .venv
.venv/Scripts/activate
python -V
pip install --upgrade pip
python -m pip install --upgrade pip
#torchのインストール
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# ctranslate2インストール
pip install ctranslate2
pip install sentencepiece transformers
pip install protobuf
# 変換
ct2-transformers-converter --model rinna/japanese-gpt-neox-3.6b-instruction-ppo --quantization bfloat16 --force --output_dir rinna-ppo-bf16
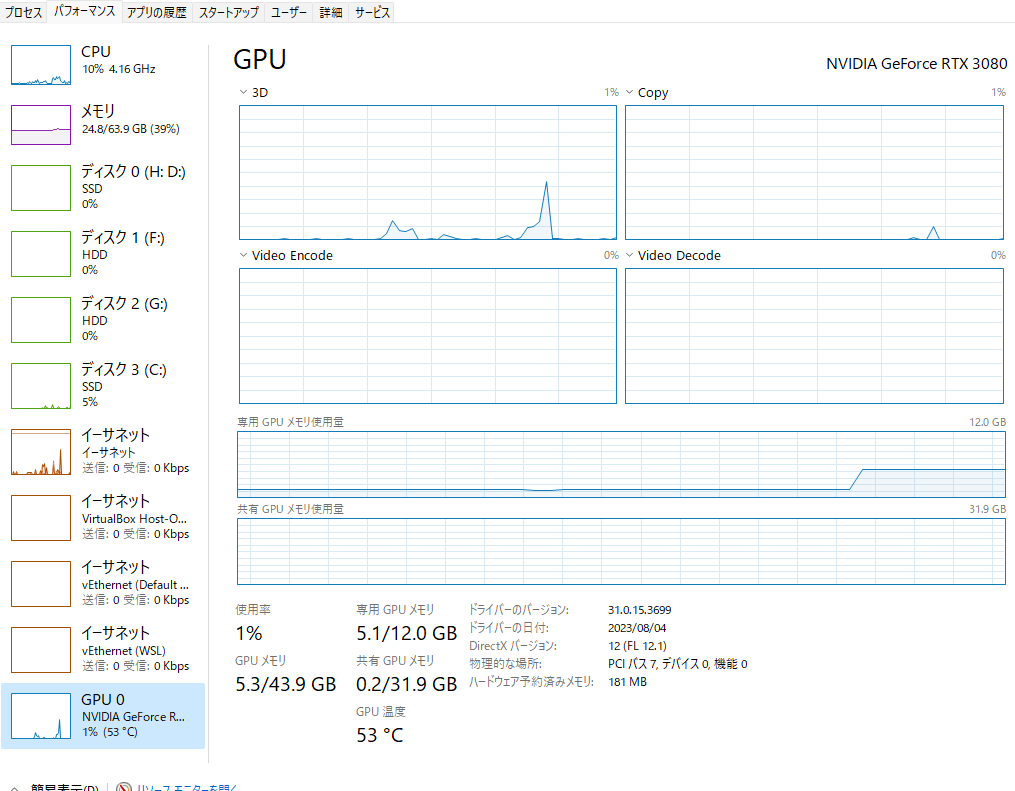
変換は、bfloat16にしてみた。この状態で動かしても6G程度。変換で使用したメインメモリは20G程度だったかな?(うろ覚え)応答も十分早く、遅延は気にならなかった。
最終的に動かしたコードは以下の通り。
import ctranslate2
import transformers
import torch
import os
os.environ["CUDA_VISIBLE_DEVICES"] = "0" #GPUを使用する場合はコメントアウトを外す
model='rinna-ppo-int8' #directory of the model
ppo = "rinna/japanese-gpt-neox-3.6b-instruction-ppo"
generator = ctranslate2.Generator(model, device="auto")
tokenizer = transformers.AutoTokenizer.from_pretrained(ppo, use_fast=False)
# プロンプトを作成する
def prompt(msg):
p = [
{"speaker": "ユーザー", "text": msg},
]
p = [f"{uttr['speaker']}: {uttr['text']}" for uttr in p]
p = "<NL>".join(p)
p = p + "<NL>" + "システム: "
# print(p)
return p
# 返信を作成する
def reply(msg):
p = prompt(msg)
tokens = tokenizer.convert_ids_to_tokens(
tokenizer.encode(
p,
add_special_tokens=False,
)
)
results = generator.generate_batch(
[tokens],
max_length=256,
sampling_topk=10,
sampling_temperature=0.9,
include_prompt_in_result=False,
)
text = tokenizer.decode(results[0].sequences_ids[0])
print("システム(ppo-ct2): " + text + "\n")
return text
if __name__ == "__main__":
# import readline
while True:
msg = input("ユーザー: ")
reply(msg)
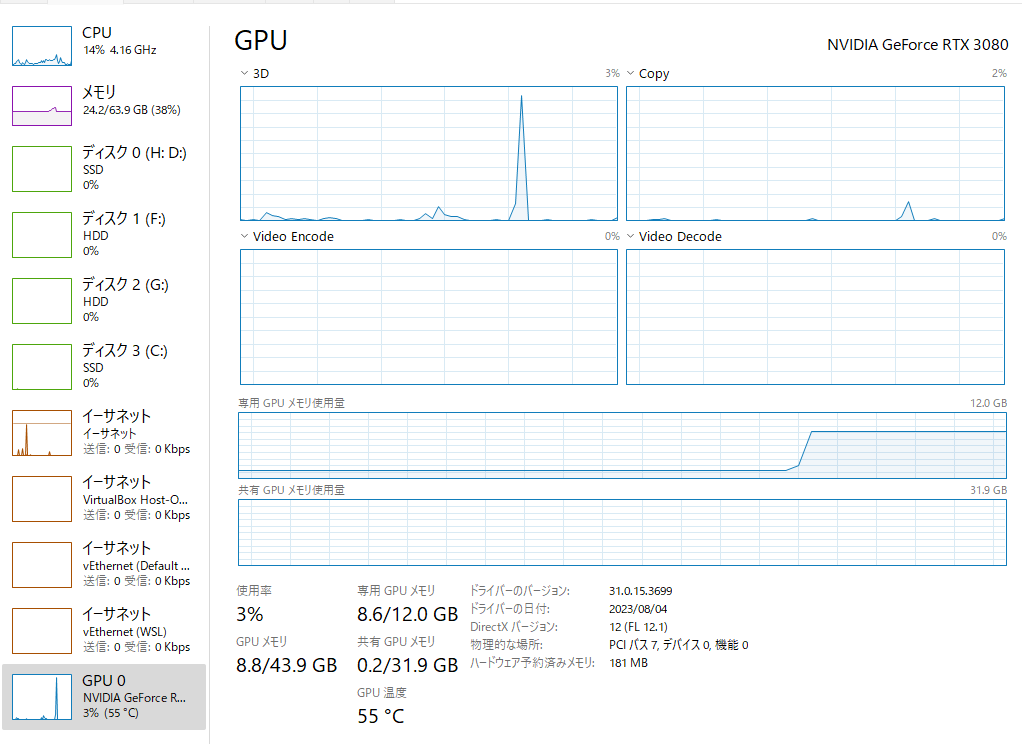
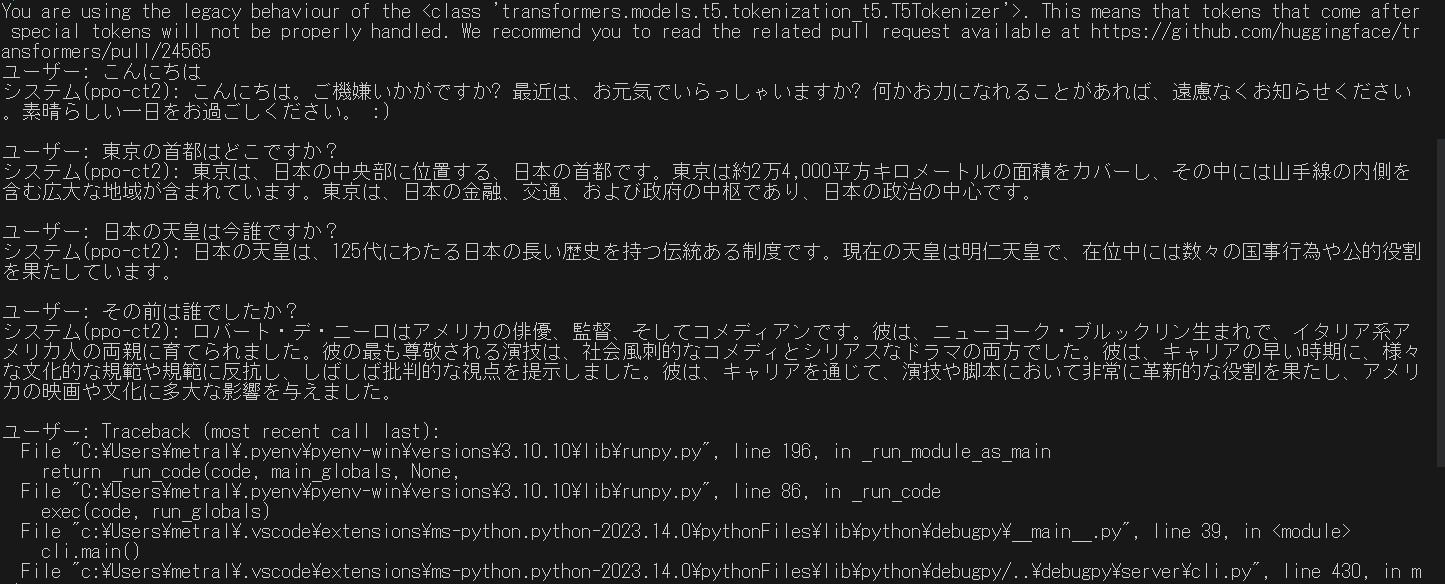
次にint8でも実行してみた。VRAMは4Gほどか?応答速度は、これも気にならなかった。応答精度も高い。